

Lange Zeit waren Datenerhebungen äußerst aufwändig. Man musste die chaotische Welt in einfache Skalen verwandeln. Etwa durch Umfragen oder Beobachtungen. Im Internet wird die Vermessung der Kommunikation hingegen einfacher: Bei sozialen Netzwerken wie Facebook oder Twitter liegen die Daten bereits in digitaler Form vor. Wenn die jeweilige Plattform es zulässt, können die dort öffentlich geposteten Daten mit einigen Zeilen Programmcode erhoben und für die Auswertung genutzt werden. Plattformen wie Facebook, Twitter und YouTube bieten solche Schnittstellen an: Informatiker, Journalisten, Wissenschaftler können damit automatisiert öffentliche Daten der Plattform erfassen und dann auswerten.
Statt Stichproben können bei sozialen Medien Vollerhebungen durchgeführt werden. Jeder öffentliche Beitrag, jeden Kommentar und jede Reaktion in den letzten zehn Jahren könnten erfasst und ausgewertet werden. „Könnten“, weil die Plattformen nicht (mehr) Zugriff auf alles geben.
Bei Facebook hat sich ein radikaler Wandel vollzogen: Als das Unternehmen damit begann Apps von Drittentwicklern auf der Facebook-Plattform zuzulassen, gab es wenige Einschränkungen. Wer einer App Zugriff auf sein Profil gab, ermöglichte ihr auch Zugriff auf alle Daten, die die Person selbst sehen konnte. Etwa private Bilder oder Nachrichten von Kontakten. Um abzufragen, ob zwei Accounts miteinander verbunden waren, reichte die ID der Accounts aus. Diese Offenheit war ein Faktor für den Erfolg Facebooks, weil Entwickler scharenweise Apps für die Facebook-Plattform entwickelten. Bis heute ist der Facebook-Login äußerst beliebt bei App-Entwicklern. Zugleich hatte diese Offenheit eine große Schattenseite: Sie ermöglichte Datenskandale wie jener der SCL Group (Cambridge Analytica). Facebook hat genau betrachtet früh auf derartige Probleme reagiert. Statt Vollzugriff auf das Profil und die Daten von Kontakten zu geben konnte Zugriff auf einzelne Bereiche gegeben werden. Name und Profil sind immer öffentlich, darüber hinaus kann der Zugriff auf Informationen wie die Mailadresse, das Geschlecht oder die Likes gegeben werden. Auch Schreibrechte sind möglich. Diese werden zum Veröffentlichen von Inhalten benötigt. Später wurden die einzelnen Berechtigungen optional gemacht, sodass es den Userinnen und Usern möglich war, Apps zu nutzen ohne alle Daten freizugeben. Schließlich hat Facebook Berechtigungen komplett gestrichen: Eine App kann seither nicht erfassen, wer die Kontakte einer Person auf Facebook sind, wenn diese die App nicht ebenfalls nutzen. Datenskandale wie jener von Cambridge Analytica sind daher bereits seit Jahren nicht mehr möglich.
Schutz der Persönlichkeitsrechte oder öffentliches Interesse?
Facebook engt schrittweise ein, welche Daten Apps aber auch Journalisten oder Wissenschaftler erfassen können. Im Frühjahr 2018 kam es zu einem weiteren radikalen Einschnitt. Alle öffentlichen Informationen einer Page ließen sich bis dahin erfassen – dazu zählten auch die Kommentare, die User öffentlich auf der Seite erfassten. Mit solchen Daten konnte man zum Beispiel auswerten, ob eine große Zahl von Usern besonders aktiv ist auf einer Seite oder ob eine Minderheit die Mehrzahl aller Postings verfasst. Genau diese Information lässt sich seit Frühjahr 2018 nicht mehr sammeln und auswerten – auch wenn es sich hier um öffentlich sichtbare Kommentare handelt. Jede Userin und jeder User kann auf jede Page gehen und sich anschauen, wer was veröffentlicht oder kommentiert hat. Über die Programmierschnittstelle (API) ist dies jedoch nicht mehr möglich. Die Kommentare selbst können ausgelesen werden, wer die Kommentare veröffentlicht hat, nicht. Deshalb ist eine Analyse, wer wie viele Kommentare und auf welchen Pages veröffentlicht hat, wie wir sie durchgeführt haben, in Zukunft nicht mehr möglich. Facebook engt hier das Blickfeld ein: Es werden damit keine privaten Daten geschützt, sondern die Auswertung erschwert, wer sich wie am öffentlichen Diskurs beteiligt.
Facebook ergriff auch weitere Schritte: Eine nachvollziehbare Hürde ist ein umfassender Prozess bis man Zugriff auf die Programmierschnittstelle bekommt. Konnte bisher jede Userin und jeder User öffentliche Daten und Daten von Personen, die der App Zugriff gegeben haben, abfragen, ist es in Zukunft nur noch verifizierten Organisationen gestattet. Es muss für jede Art des Datenzugriffs eigens erklärt werden, warum er nötig ist und wie er genutzt werden wird. Die Apps werden von Facebook getestet und erst dann freigegeben. Die Organisation muss ihre Echtheit nachweisen.
Twitter hat einen anderen Weg eingeschlagen. Dort wird der Zugriff auf die öffentlichen Daten verkauft. Es gibt eine kostenlose API, über die Userinnen und User Lese-, Schreib-, und Direktnachrichten-Zugriff geben können. Ebenfalls kostenlos ist der Zugriff auf öffentliche Tweets der letzten sieben Tage, jedoch ist stark beschränkt, wie schnell die Tweets abgefragt werden können. Eine Premium-API gibt Zugriff auf das gesamte Archiv öffentlicher Tweets. Somit sind Auswertungen von Tweets nicht nur einfacher möglich, sondern auch zuverlässiger. Eine Folge davon ist, dass es gemessen an der Nutzung überproportional viele Untersuchungen mit Twitter-Daten gibt. Einfach gesagt: Dass so viele Studien die Kommunikation auf Twitter messen, liegt wohl auch daran, dass es einfacher ist, Analysen auf Twitter als auf Facebook zu betreiben.
Die Schwächen der Facebook-Schnittstelle
Das Dilemma für alle Datenauswertungen auf Facebook ist: Es gibt dabei Datenunsicherheiten. Zum Beispiel stellt sich die Frage, wie zuverlässig die Programmierschnittstelle ist. Werden immer die gleichen Daten ausgegeben? Geringe Schwankungen sind zu erwarten, weil sich die Pages selbst verändern. Selbst wenn man den gleichen Zeitraum abfragt, können bei unterschiedlichen Abfragen leicht unterschiedliche Ergebnisse gesammelt werden, weil Userinnen und User sowie Pages zwischendurch Beiträge, Kommentare oder Reactions löschen und/oder Neues hinzukommt. Facebook nutzt nicht einen Server, sondern tausende, die miteinander synchronisiert werden, sodass es passieren kann, dass man von unterschiedlichen Orten leicht unterschiedliche Ergebnisse bekommt, weil man auf unterschiedlichen Servern landet.
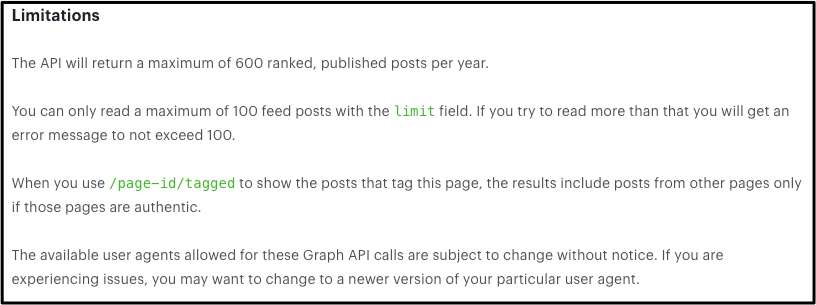
Darüber hinaus gibt es Bugs, die Inhalte fehlerhaft ausgeben. Seit mindestens 2015 gab es einen oder mehrere Bugs, die verhindert haben, dass alle Beiträge von Pages ausgegeben wurden. Dies gab Facebook im Jahr 2015 und im Jahr 2018 zu. Obwohl Facebook mehrmals behauptet hat, der Bug wurde gefixt (was möglich ist, wenn es unterschiedliche waren), scheint dieses Problem nun nicht mehr von Facebook ausgebessert zu werden: Mittlerweile bezeichnet Facebook dies als eine offizielle Limitierung der Programmierschnittstelle. Dies hat zur Folge: Pages, die in einem Jahr mehr als 600 Beiträge veröffentlichen, werden nicht vollständig ausgegeben.
Quelle: facebook.com
Für alle Datenauswertungen, die Pages mit hoher Postingfrequenz miterfassen, führt dies zu einem Problem: Man muss davon ausgehen, dass Facebooks eigene Programmierschnittstelle einen kleinen Teil der Beiträge nicht mitausliefert. Im Digitalreport war dies bei der Page von Heinz-Christian Strache der Fall: Diese Facebook-Seite postet deutlich mehr als die anderen Accounts. Facebook sagt, dass es über die Programmierschnittstelle maximal 600 Beiträge auswirft. Was es leider nicht verrät ist, nach welcher Logik diese Beiträge ausgewählt werden. Wir haben im Laufe eines Monats mehrere Erhebungen gemacht und verglichen, welche Beiträge vorhanden bleiben und welche verschwinden. Zwischen der ersten Erhebung am 11. Juni und der letzten am 2. Juli 2018 sind 72 Beiträge im beobachteten Zeitraum 1.1.2018-1.6.2018 „verschwunden“. Über die Direktlinks sind die Beiträge weiterhin abrufbar; sie wurden also nicht gelöscht. Es ist kein Muster erkennbar, welche Beiträge nicht mehr abrufbar sind. Es gibt zahlreiche Beiträge mit weniger Interaktionen, die in der letzten Erhebung noch vorhanden sind. Somit werden Auswertungen von Facebook Pages, die viele Beiträge veröffentlichen unverlässlicher, je später im Jahr sie durchgeführt werden. Um möglichst sichere und vollständige Daten erheben zu können, haben wir uns dazu entschlossen, eine Kombination aus zwei Datenerhebungen als Grundlage für die Auswertung zu nutzen, da wir in dieser den vollständigsten Überblick haben.
Bei Twitter gibt es bei der kostenlosen API ebenfalls eine Datenunsicherheit, die noch nicht ausreichend untersucht wurde. Twitter spricht von einem Fokus auf Relevanz statt Vollständigkeit. Die kostenpflichtige Premium-Version verspricht Vollständigkeit.
In der Theorie könnte es sehr leicht sein, öffentliche Daten über Facebooks Schnittstelle auszuwerten: In der Praxis gibt es Einschränkungen, die Auswertungen erschweren (oder im Fall der User-Kommentare) komplett verunmöglichen. Und es scheint so zu sein, dass Facebook diese öffentlich auswertbaren Daten weiter einschränkt. Dies erschwert die Recherche zur Diskussionskultur auf sozialen Medien.
Die Neuerung: Wenige sehen nun vieles
Facebook hat schon länger zahlreiche Wissenschaftlerinnen und Wissenschaftler angestellt, die nicht zur Zugriff auf Daten haben, sondern teilweise signifikant in die Funktionsweise der Plattform eingreifen. Etwa um herauszufinden, wie Userinnen und User auf einen Feed von eher positiven oder eher negativen Meldungen reagieren. Auch Kooperationen mit externen Forscherinnen und Forschern hat es in der Vergangenheit gegeben. Dort hat aber Facebook Einfluss darauf welche Daten wie genutzt und veröffentlicht werden.
Nun wird der Zugriff für einen Teil der Wissenschafts-Community massiv ausgebaut: Am 11. Juli 2018 wurde Social Science One gestartet. Es handelt sich hier um eine Organisation, die explizit nicht zu Facebook gehört und von sieben Non Profit Organisationen finanziert wird. Über diese soll in Zukunft Forschung von Social-Media-Plattformen möglich sein. Der erste Datensatz, der darüber verfügbar gemacht wird, sind alle URLs, die mindestens 20-mal auf Facebook geteilt wurden. Der Datensatz ist jedoch nicht für alle verfügbar, sondern nur für Auserwählte: Wissenschaftlerinnen und Wissenschaftler müssen sich dafür bewerben. Ein Komitee sucht dann Personen und Gruppen aus, die neben Zugriff auf die Daten auch eine Finanzierung bekommen können.
Sie erhalten die Daten jedoch nicht direkt, sondern müssen aufgrund von Beispieldaten ein Programm schreiben, das die Daten auswertet. Das Programm wird dann Social Science One übergeben, die es auf dem gesamten Datensatz ausführen und überprüfen, ob das Ergebnis lediglich anonymisierte Daten enthält. Wenn dies der Fall ist, werden die angesuchten Daten den Forscherinnen und Forschern gegeben. Facebook hat keinen Einfluss darauf, wer die Daten untersuchen darf oder was veröffentlicht wird. Für die Wissenschaft ist das ein umständlicher, aber nachvollziehbarer Prozess, da eine Weitergabe riesiger Datenmengen auch die Gefahr birgt, dass einzelne Nutzerinnen und Nutzer wieder identifiziert werden können. Der nun eingeführte Prozess soll ermöglichen, dass Forscherinnen und Forscher basierend auf großen Datenmengen Auswertungen machen können – aber nicht Zugriff auf alles erhalten. Eine Schattenseite hat dieses System jedoch: Wer kein Mitglied einer Forschungseinrichtung ist, kann sich hierfür nicht bewerben – im neu eingeführten Setting können auch Redaktionen nicht um Zugriff auf Facebooks Datenschatz ersuchen. Während die Recherchemöglichkeiten für einzelne Forscherinnen und Forscher aktuell also erweitert werden, wird der Einblick für alle anderen interessierte Gruppen hingegen eingeengt.
Die Methodik dieser Analyse erklärt Luca Hammer auch hier.
No Comments